
The Syniti
Data Matching Engine
The foundation of our matching engine is designed to deliver results that mirror human perception, at scale and at incredible speed.






An AI Matching Engine Designed for Contact, Business and Operational Data
Using purpose-built Artificial Intelligence, proprietary phonetic and fuzzy matching algorithms, context-sensitive lexicons, and a contextual matching engine, our software defeats the errors, inconsistencies and challenges commonly found in contact and business data. Like these…

The Problem with Conventional Solutions
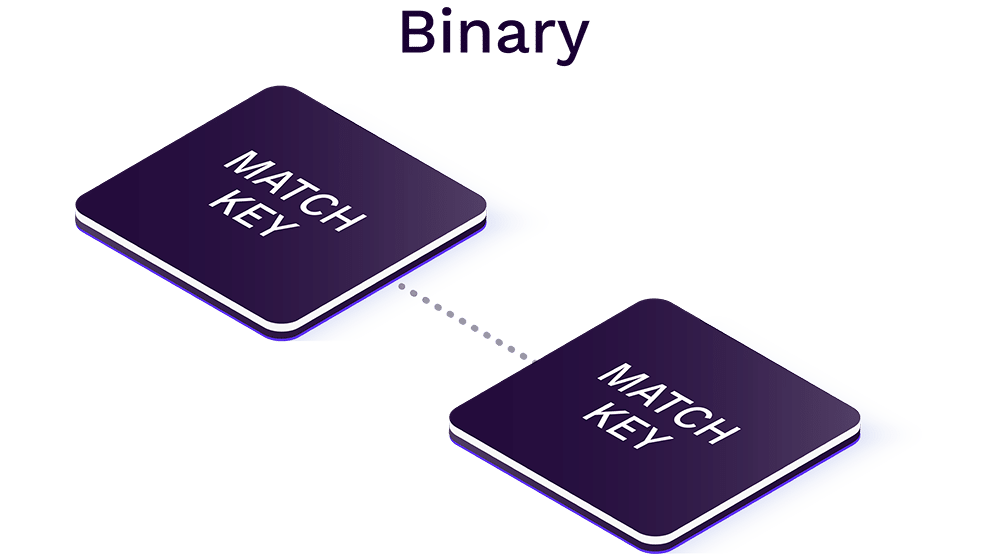
A conventional data matching service requires a user to define fuzzy matching logic by using a combination of functions and off-the-shelf data matching algorithms, used to produce an alphanumeric value. This alphanumeric value, or ‘match key’, forms the basis for comparing two records together and ultimately finding matches.
Relying solely on extended match keys to find matching records presents two major problems:
- Match keys require unusually clean data that has been standardized, validated, and conforms to a consistent layout. An expert user or data scientist might be required to prepare messy data – these people are scarce and waiting for them can cause significant delays.
- The errors commonly found in contact and business data will cause your matching logic to break all too often, regardless of how much cleaning, standardizing, and restructuring you do.
The Syniti Difference
Unlike a conventional data matching service, the Syniti matching engine doesn’t rely on extended match keys to find a match. Instead, it compares larger groups of records contextually, using all the relevant attributes of your data to get a highly granular match score that reflects the similarity between records. This makes it superior to standard fuzzy matching approaches.
Sound familiar? It’s the same process humans use to make comparisons.

Where's the AI?
Just inventing a Matching Engine with results like human perception but at scale, wasn’t enough.
To enable our matching engine to produce answers faster, we had to remove the need for manual preprocessing and focus on accessibility for people who don’t live and breathe data. To achieve this, we tapped into Artificial Intelligence methods for our data matching service.
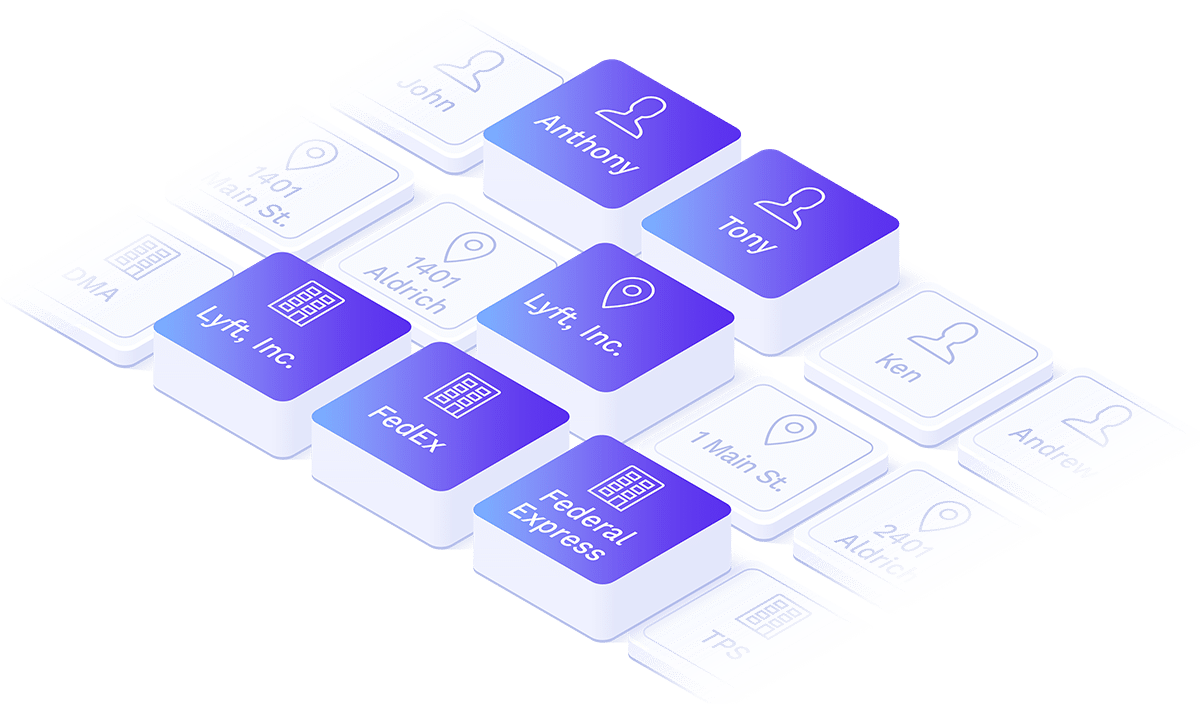
Natural Language Processing (NLP) refers to AI methods concerned with understanding human language as it might be spoken or heard. Using NLP techniques like lexical semantics, the engine develops an understanding of your data based on what it is and not where it resides in a table.
Like you, the engine also understands variant forms of names (like Tony for Anthony) and acronyms (such as IBM for International Business Machines). It also understands that job titles, company names etc. are often entered in the address lines and the myriad of other data entry issues that often arise.
A Smarter Way to Match
Making Sense of Your Data
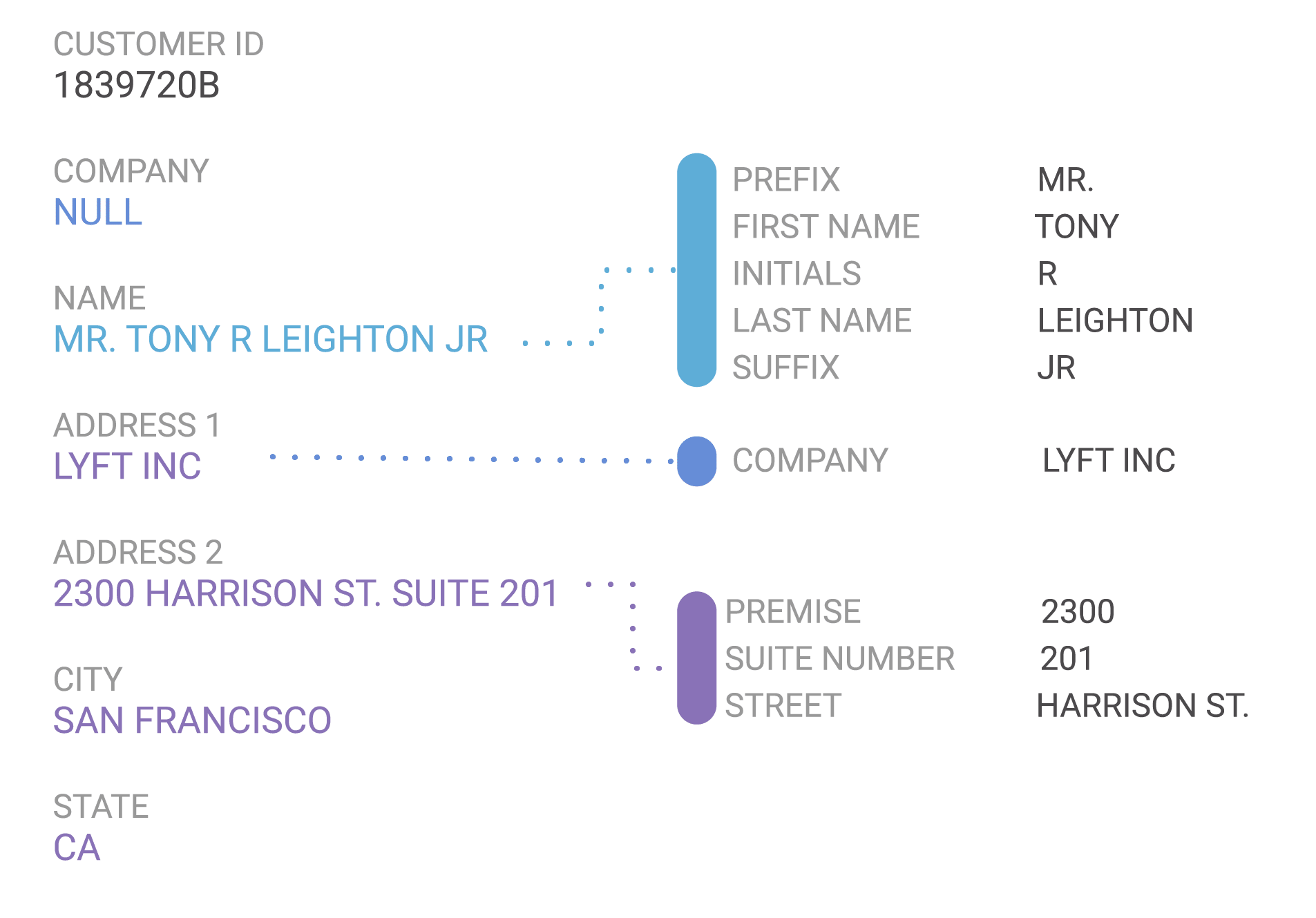
It all starts as your data enters the matching engine, where it is first normalized. By understanding the language of contact data, the engine breaks down complex, concatenated fields into their constituent parts. It handles foreign character sets and relocates misplaced data as necessary. The quality of fields like name, address, and email are assessed and the resulting quality scores give the engine guidance on the trustworthiness of individual data attributes. It may be garbage in, but that doesn’t mean it has to be garbage out!
How Do You Pronounce That?
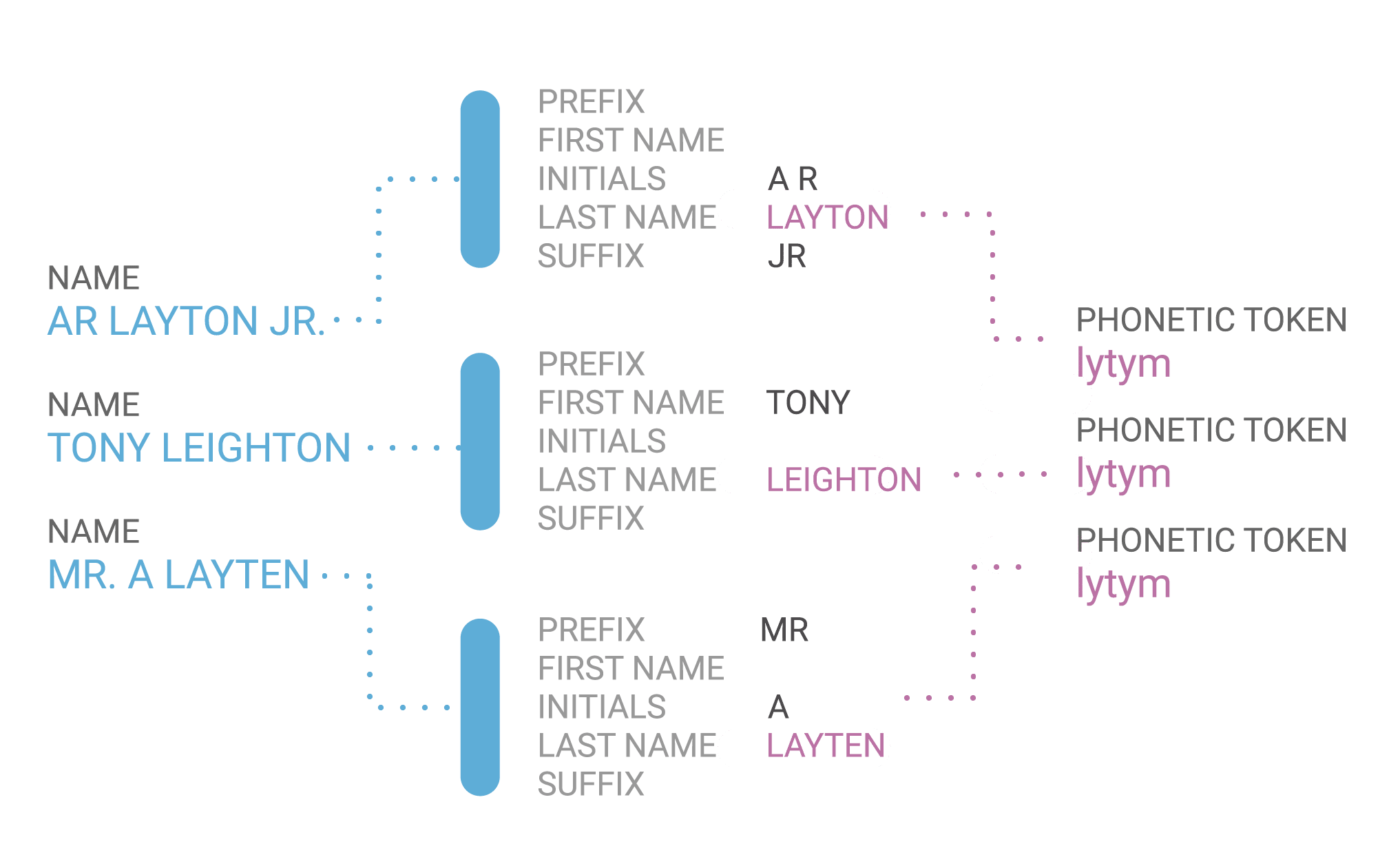
After normalization, our matching engine uses intelligent phoneticization. Once its isolated values like first name, company name, street name, and city, it can generate phonetic tokens for these fields to help cope with errors in your data.
Instead of using off-the-shelf algorithms like Soundex, Double-Metaphone or Metaphone 3 that were never designed for the nuances of contact and business data, the Syniti matching engine uses a proprietary phonetic algorithm that breaks each word into syllables and works out the sound of each syllable.
While picking up names that sound the same but are spelled quite differently like Leighton and Layton, our phonetic data matching algorithm rejects different-sounding names which these other algorithms equate, like Mason and MacEwan.
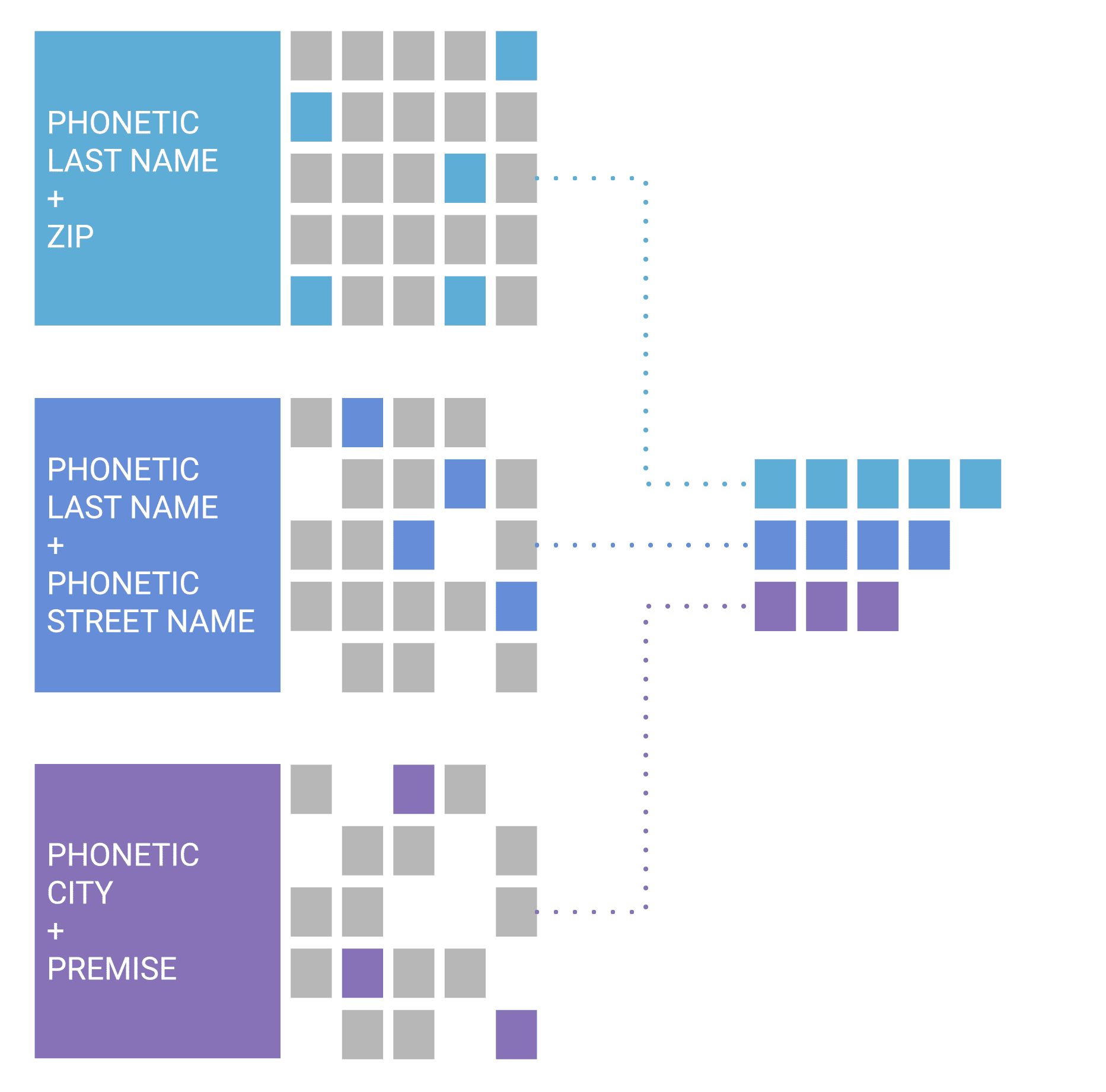
Finding Potential Matches
After the matching eng has made sense of the data, it uses the normalized and tokenized values to seek out potentially similar records. It’s important to note that we aren’t finding matches yet, we’re simply identifying groups of records that are signalling further comparison is warranted.
Unlike a conventional data matching service, this doesn’t depend on any single data point being reliably accurate, consistent, or even present. Using the values generated from the previous steps, the matching engine is able to compare two records that may have nothing exactly the same.
Why candidate groups? The short answer is scale. Syniti matching engine can run efficiently on over a billion records and perform real-time lookups on massive datasets. Without candidate grouping, this wouldn’t be possible even on much smaller files.
Reflecting Human Perception at Scale
Unlike humans, our matching engine doesn’t get tired – its job is to enable you to accept the vast majority of matches without having to review them, so there are very few that could be considered “in the gray area.” Here’s how it does this…
As candidate groups are created, our scoring algorithms compare the records contextually. All the relevant data is graded for similarity and assigned a component score for each aspect of the data.
Where a conventional data matching service replies on the comparison and scoring of match keys, our engine is comparing and scoring the contact name, company name, address, zip, telephone, email, and even custom fields individually – so you can score things like website, account numbers, date of birth, license plates or any other information you hold.
Finally, the component scores are brought together into a single composite score which establishes the overall similarity between the records.
To learn more about what’s going on under the hood of the Syniti matching engine, download our datasheet.

Ready to get started?
You've met your match. Syniti ignites business growth through better data.
More about Matching
Syniti and 360Science: We Met Our Match
Dedicated to providing global enterprises access to accurate data, when they need it, Syniti recently acquired 360Science, a leader in data matching solutions.