Data Matching Software
Cure your duplicate data pain
with smarter matching.
Unlock a clear, connected view of your customer, business, and ERP data.





Catch Duplicates Before They Catch You
Staying on top of data quality can be tricky when you’ve got contact, business, and operations data stored across various systems. Pesky hidden duplicates may seem like a minor problem, but can cause major pain in the not-so-distant future.
Syniti Match uses AI-powered technology to rapidly and reliably find duplicates within your data, no matter its source or structure.
Duplicate Data Cost Calculator
How much is duplicate data costing your business?
Cost Profile Scenario Comparison
*This tool is provided solely for illustrative purposes. Syniti disclaims all representations and warranties as to the information provided, and any resulting calculations should not be construed as an offer.
Human-like intelligence, superhuman scale
Syniti has successfully replicated the natural intelligence humans use when forming comparisons – and our matching engine delivers that capability at scale.
Our software utilizes AI, proprietary phonetic and fuzzy matching algorithms, and context-sensitive lexicons to evaluate matches contextually the same way a human would.
This enables the software to “understand” your data based on what it is rather than where it resides in a table.
Precision is power.
Fine-tuned AI maximizes matches found while minimizing false positives.
We’ll handle the heavy lifting.
Reduce strain on technical resources by bringing your party data as is, zero wrangling required.
Deploy how and where you’d like.
Cloud-native software supports hybrid and full cloud deployment options, offering complete flexibility on how and where your matching jobs run.
Run match jobs without breaking a sweat.
Default match settings are based on your data, with the flexibility to adjust for specific use cases. Smart settings intuitively scale with the growing volume and variety of your data, empowering users to perform complex jobs with ease.
The Greatest Evolution in Data Matching Technology in a Lifetime.
With 30+ years of development and customer experience behind it, Syniti Match continues to deliver. We've spent years perfecting the science of matching to help data-driven organizations solve their most complex challenges. The engine we've built is flexible and scalable to help businesses match billions of records, and from just about any source or enterprise system to help you make smarter decisions -- faster.
Architecture That Helps You Match Faster
Match billions of records in minutes with batch ingestion to correct duplicate data. Find matches in a sub-second with real-time ingestion to prevent duplicate record creation.
Our powerful engine’s dual-matching architecture is able to tackle thousands, millions, or even billions of records at lightning speed.

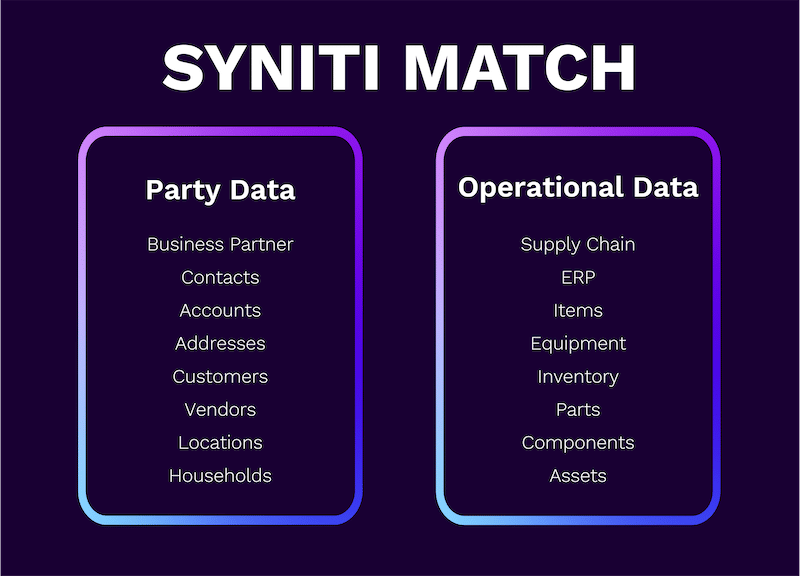
High-Value Matching for Your Operational Data
Ready to go beyond party data matching? Syniti matches the data behind your business operations, also known as operational data. By matching this ERP and supply chain data – such as items, equipment, parts, assets, business partners, and SKUs, enterprises can reduce spare parts, ensure a reliable supply chain, and save millions in working capital.
Customer Success Stories
One Duplicate Is All It Takes: How to Prevent the Bad Data Domino Effect
Join Syniti in our latest webinar to find out what it takes to establish a proactive data quality strategy, and which capabilities enterprises should seek from a data matching solution to achieve this? Learn how far-reaching the impact of a single missed duplicate can be, how Syniti’s real-time data matching technology delivers preventive detection, and how to begin building your organization’s proactive data quality strategy.

Powering iconic enterprises with better data matching
Trusted and understood data never goes out of style. Here are some situations in which Syniti data matching can help you elevate your performance.
Combat CRM Duplication
Achieve a single, 360 view of the customer to deliver consistent, high-quality experiences and win the battle against broken customer journeys.
Simplify SAP Migrations
Maintain a system of clean data while migrating to SAP S/4 HANA by streamlining business partner harmonization with complete and accurate customer and supplier data.
Transform Vendor Management
Match parts and align them with vendors to identify qualified volume discounts and help find millions in potential procurement savings.
Unlock Greater Inventory Visibility
Identify and correct duplicate, incomplete, and mismatched inventory information data to deliver greater visibility into ERP and supply chain data.
More from Syniti
What Makes Up Next-Gen Data Matching?
A truly intelligent data matching solution interacts with your data and revolutionizes how users perform matching tasks.